Universal Infrastructure: Solving the Portability Gap with BigConfig
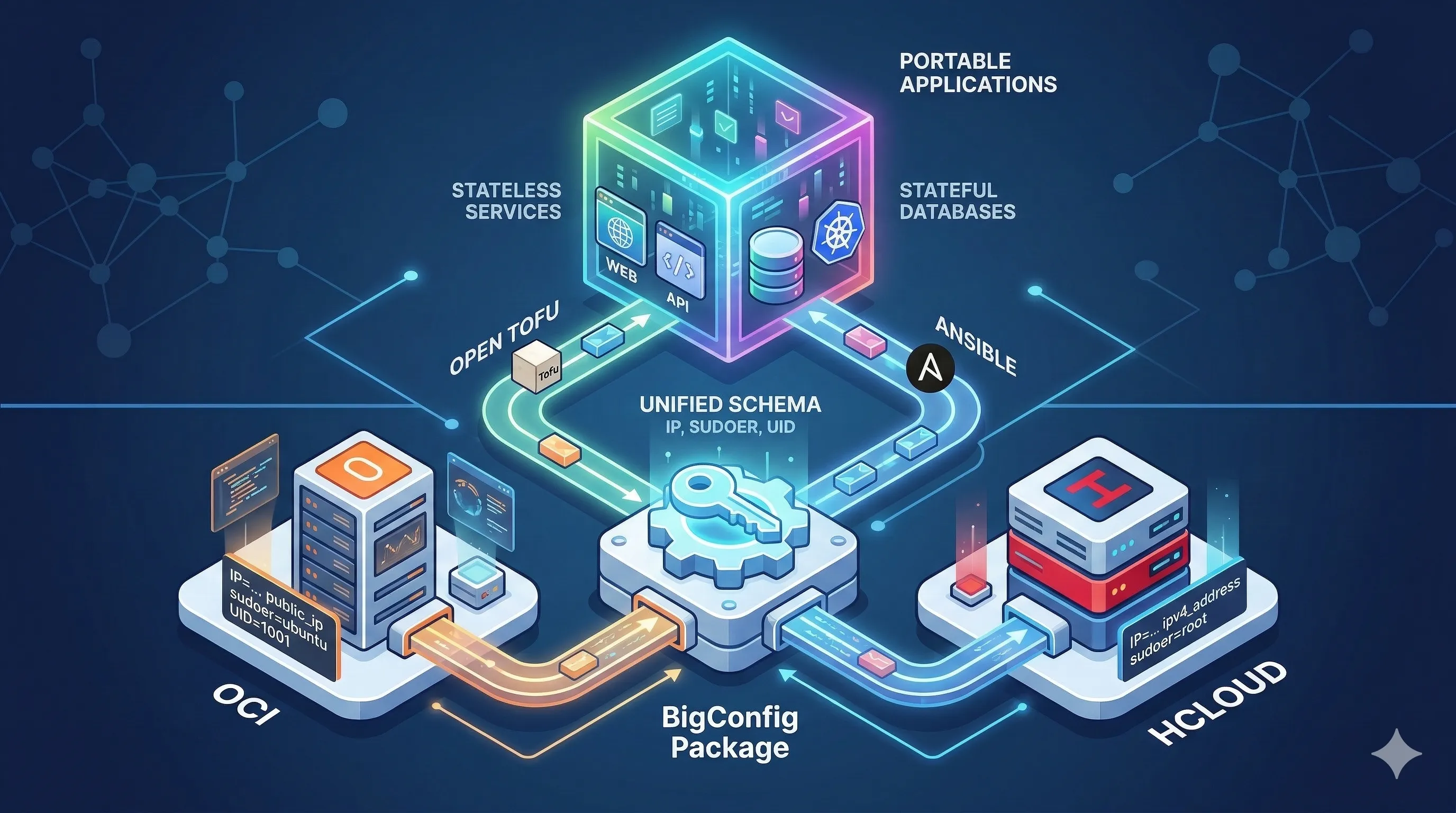
The primary challenge with Terraform and Ansible has always been portability. It is notoriously difficult to take a solution written for one environment and apply it to another without significant manual adjustments. Kubernetes achieved its massive success by leveling this playing field. With tools like Helm, you have a package manager that allows you to install applications without worrying about whether you are on-prem or using a specific hyperscaler.
However, in the world of Kubernetes, a common sentiment is to avoid stateful applications like databases unless you have mastered every technical nuance. Most internal platforms use Kubernetes for stateless services while relying on managed databases provided by the hyperscaler.
BigConfig Package changes this dynamic by enabling the creation of universal applications that are both stateful and stateless. Walter , the first application built with BigConfig, demonstrates this by deploying seamlessly across Oracle Cloud and Hetzner.
The Portability Challenge
Section titled “The Portability Challenge”Infrastructure is rarely uniform. When moving between providers, you encounter several inconsistencies:
- The IP address property is named differently depending on the provider.
- The default SSH user varies.
- The UID of the default user is often inconsistent.
The solution involves defining a standardized schema for output parameters in every main.tf file:
output "params" { value = { ip = oci_core_instance.ampere_vm.public_ip sudoer = "ubuntu" uid = "1001" }}output "params" { value = { ip = hcloud_server.node1.ipv4_address sudoer = "root" }}Gluing Infrastructure to Configuration
Section titled “Gluing Infrastructure to Configuration”This approach effectively glues the OpenTofu infrastructure step to the Ansible configuration step. By parsing the JSON output from the infrastructure layer, we can pass critical connection data directly into the workflow:
(defn opts-fn [opts] (let [dir (workflow/path opts ::tools/tofu)] (merge-with merge opts {::workflow/params (if (fs/exists? dir) (-> (p/shell {:dir dir :out :string} "tofu output --json") :out (json/parse-string keyword) (->> (s/select-one [:params :value]))) {:ip "192.168.0.1" :sudoer "ubuntu"})})))As long as the OpenTofu step adheres to the schema by providing an ip, sudoer, and uid, any new hyperscaler can be integrated into this BigConfig Package.
Handling Distribution Differences
Section titled “Handling Distribution Differences”What about variations in Linux distributions? This can be handled within Ansible or, similar to our Terraform approach, by using different source files based on the distribution.
(defn tofu [step-fns opts] (let [opts (workflow/prepare {::workflow/name ::tofu ::render/templates [{:template (keyword->path ::tofu) :overwrite true :hyperscaler "hcloud" :transform [["{{ hyperscaler }}"]]}]} opts)] (workflow/run-steps step-fns opts)))The power lies in the dynamic folder pathing. By using the template variable "{{ hyperscaler }}" for the hyperscaler, the directory containing the infrastructure code becomes dynamic. This allows us to share core Ansible logic while diverging where necessary, ensuring the code remains clean and manageable.
Conclusion
Section titled “Conclusion”By standardizing the handshake between infrastructure provisioning and configuration management, BigConfig Package removes the friction typically found in multi-cloud deployments. This modular approach ensures that your automation remains truly portable, allowing stateful workloads to run wherever they are needed most without being locked into a single provider’s ecosystem.
Would you like to have a follow-up on this topic? What are your thoughts? I’d love to hear your experiences.